
Kiedy w 1989 roku Tim Berners-Lee wynalazł World Wide Web (WWW) [1]https://home.cern/science/computing/birth-web/short-history-web, tak zwana „sieć” miała być miejscem powstałym z połączenia dynamicznie rozwijających się technologii komputerowych, dzięki którym możliwa byłaby „automatyczna” wymiana informacji między ośrodkami naukowymi i kadrą badawczą na całym świecie.
Projekt WWW składał się z dwóch kluczowych podmiotów: hipertekstu, czyli dynamicznego sposobu organizacji i prezentacji informacji, teraz potocznie nazywanego „linkami”, który umożliwiłby użytkownikom przemieszanie się między różnymi treściami, zlokalizowanymi w dowolnych miejscach w sieci. Wszystko to miało być możliwe za pomocą prostej interakcji – pojedynczego kliknięcia przyciskiem myszy w niebieski, podkreślony fragment tekstu. Drugim elementem była „przeglądarka”, specjalny rodzaj interfejsu użytkownika, którego głównym zadaniem jest wymiana danych z serwerem i „rysowanie” pobranych informacji na ekranie. W niedalekiej przyszłości sieć Tima Bernersa-Lee obejmie swoimi nićmi cały świat i zrewolucjonizuje sposób, w jaki ludzie wyszukują i przetwarzają informacje.
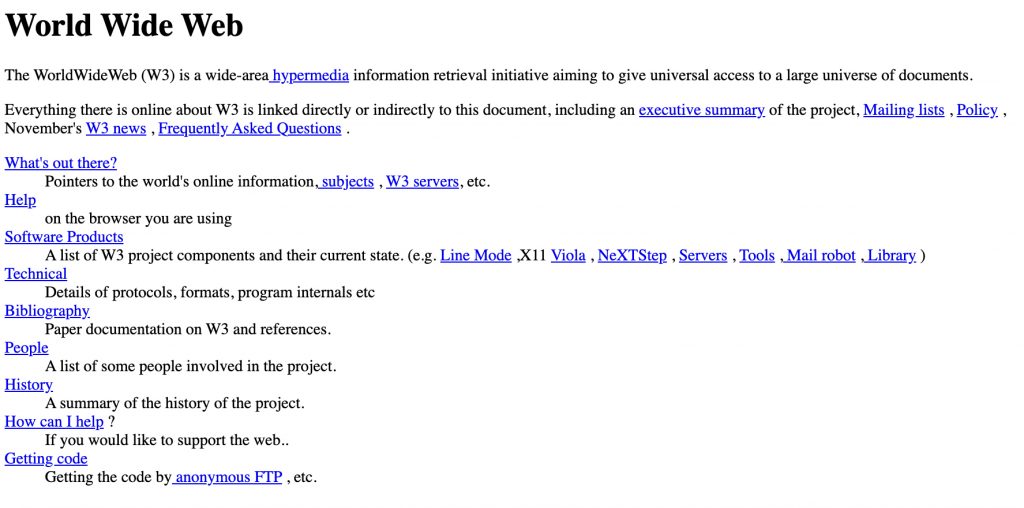
Pierwsza strona internetowa, choć brutalna w swojej prostocie, ma coś, czego brakuje większości stron WWW dzisiaj – jest szczera z odbiorcą. Nie próbuje oszukać czy zwieść użytkownika. Proste interakcje – czarne do czytania, niebieskie do klikania. Stuprocentowa koncentracja na treści. Hipertekstowa struktura, która szanuje swoich gości. O ilu dzisiejszych stronach internetowych możemy powiedzieć to samo?
W sieci najczęściej czegoś szukamy, mówiąc językiem architektury informacji, chcemy spełnić swoją potrzebę informacyjną. Proces wyszukiwania został opisany w 1989 przez Marcia J. Bates i nazwany modelem „zbierania jagód” [3]https://pages.gseis.ucla.edu/faculty/bates/berrypicking.html, ponieważ z każdą odwiedzoną stroną internetową lub dokumentem zbieramy nowe informacje (to jest dowiadujemy się czegoś nowego), a to wpływa na zmianę naszego pierwotnego zapytania, które wpisaliśmy w wyszukiwarkę. Zanim znajdziemy to, czego szukamy, zanim zaspokoimy potrzebę informacyjną, prawdopodobnie odwiedzimy kilka lub kilkanaście różnych stron internetowych. I tutaj zaczynają się schody…
Wyszukiwanie informacji samo w sobie jest zajęciem obciążającym poznawczo, a do pokonania mamy tor przeszkód, który został pieczołowicie przygotowany niemal na każdej stronie, którą odwiedzamy po raz pierwszy.
Jakie „atrakcje” czekają nas w tym wątpliwie zorganizowanym małpim gaju?
- Okno ze zgodami związanymi z przetwarzaniem naszych danych.
- Baner z informacjami o ciasteczkach.
- Pytanie o lokalizację.
- Prośba o włączenie powiadomień.
- Chatbot, który koniecznie chce z nami pogadać.
- Czerwona kropeczka symbolizująca pilną wiadomość do nas, mimo tego, że nawet nie mamy konta w tym serwisie i niemożliwe, by faktycznie czekało na nas coś pilnego.
- Popup zachęcający do płatnego abonamentu, dzięki którym odblokujemy dostęp do ekskluzywnych treści i oczywiście pełnej treści artykułu o clickbaitowym tytule, którego nawet nie chcemy czytać.
- Newsletter, aby być na bieżąco. Nieważne, że nawet jeszcze nie zobaczyliśmy treści strony.
- I w końcu załaduje się pełnoekranowa reklama w tle całej strony – przecież ta grafika potrzebowała czasu na pobranie – dobrze, że mieliśmy co robić w międzyczasie.
Dodatkowo wyobraźmy sobie, że otwieramy tę stronę na smartfonie, jesteśmy osobą o mniejszych kompetencjach cyfrowych, mamy małą wadę wzroku i palce, którym trudno jest trafić w mikroprzyciski, umieszczone za każdym razem w innym miejscu. W tym wrogim środowisku każdy missclick ma swoją cenę – niezrozumiałą teleportację do innej strony. Strzałka „wstecz” oczywiście nie zadziała, bo jesteśmy już w nowej karcie. Przecząc podstawowej heurystyce Nielsena [4]https://www.nngroup.com/articles/ten-usability-heuristics/, uniemożliwiliśmy użytkownikowi popełnienie błędu i powrót do poprzedniego stanu rzeczy. Wątpliwej przyjemności przygoda zaczyna się od nowa, jeżeli użytkownik ma jeszcze siłę na ponowne rozpoczęcie tej podróży.

Oczywiście sieć – tak samo jak ludzie, którzy ją tworzą – nigdy nie była idealna. Samootwierające się okna przeglądarek, które samoistnie pączkowały na ekranie, reklamy z muzyką, wirusy schowane pod niepozornie wyglądającymi linkami – to elementy, które były standardem w internecie z początku lat 2000. Z czasem świat WWW zrozumiał, że potrzebne jest wyznaczenie standardów i na przykład uniemożliwienie witrynom samoistnego otwierania nowych okien przeglądarki. Dlaczego nie mamy takich standardów w kontekście chociażby polityk cookies i RODO?
Obecnie każda strona internetowa, która przechowuje dane użytkowników z Unii Europejskiej, musi zaprojektować i wdrożyć własne interfejsy do wyświetlania i obsługi na przykład polityki RODO, co wymusza na użytkownikach konieczność uczenia się od nowa sposobu „rozbrajania” tych mikrointerfejsów. Brak standardów dotyczących projektowania tego typu okien stwarza pokusę do wykorzystania przez biznes dark patternów, czyli wzorców projektowych, mających celowo wprowadzić użytkowników w błąd lub manipulować nimi, aby uzyskać określoną reakcję.
W tym przypadku pożądaną reakcją biznesu będzie zdobycie pseudoświadomej zgody (poprzez kliknięcie użytkownika w prominentny przycisk: „Przejdź do serwisu”) na tworzenie bardzo szczegółowych profili zbudowanych na podstawie między innymi odwiedzonych stron, zakupów online i szczegółowych danych o urządzeniu. To właśnie dzięki tym danym, w zupełnie magiczny sposób, na Youtubie pojawia nam się reklama odkurzacza, o którym pisaliśmy z mamą na Messengerze.
Ale przecież mamy wybór!
Zawsze możemy przejść do „zaawansowanych ustawień przetwarzania danych”, aby zobaczyć listę kilkunastu zgód i kilkudziesięciu* „zaufanych partnerów”, do których przekazywane są informacje o naszej historii przeglądania. Kto z nas ma siłę, aby na każdej odwiedzonej stronie poświęcić kilka minut i wykonać kilkadziesiąt (!) dodatkowych kliknięć, żeby „dostosować preferencje witryny”?
Oczywiście istnieją lepiej zaprojektowane konfiguratory, które pozwalają na przykład za pomocą jednego kliknięcia zabronić śledzenia i zamknąć irytujące okienko, ale większość z nich jest labiryntami, celowo zwodzącymi użytkowników. Niestety tego typu pułapki są dziełem całych zespołów projektowych. Zapewniam, że w każdej szanującej się korporacji w takim projekcie wzięło udział co najmniej kilkanaście osób, które nie wyznają projektowania zorientowanego na użytkownika (user centered design, UCD), a projektowanie zorientowane na biznes. Chyba żaden projektant będący przy zdrowych zmysłach, dbający o użyteczność i etyczność tworzonych rozwiązań, nie chciałby, aby rozbrajanie bomby z wyskakujących okienek przerywało pieczołowicie projektowane doświadczenie przy pierwszym korzystaniu z produktu.
Myśląc o internecie przyszłości, sobie i Tobie, Drogi Czytelniku, życzę stron internetowych, które przede wszystkim nie gromadzą żadnych danych, poza tymi absolutnie niezbędnymi do ich poprawnego działania. Lub powstania zintegrowanych mechanizmów, umożliwiających konfigurowanie ustawień dotyczących przekazywania danych, lokalizacji, powiadomień i tym podobnie po stronie przeglądarki – tak, aby raz skonfigurowane ustawienia oszczędziły nam kilkunastu kliknięć lub „tapnięć” w dotykowy ekran, na każdej nowo odwiedzonej stronie internetowej.
*Ich naprawdę tyle jest. Zachęcam do sprawdzenia tego na dowolnym dużym portalu z aktualnościami.
Przypisy